مجموعه ارقام دستنویس هدی که اولین مجموعهی بزرگ ارقام دستنویس فارسی است، مشتمل بر 102353 نمونه دستنوشته سیاه سفید است. این مجموعه طی انجام یک پروژهی کارشناسی ارشد1 درباره بازشناسی فرمهای دستنویس تهیه شده است2. داده های این مجموعه از حدود 12000 فرم ثبت نام آزمون سراسری کارشناسی ارشد سال 1384 و آزمون کاردانی پیوستهی دانشگاه جامع علمی کاربردی سال 1383 استخراج شده است. خصوصیات این مجموعه داده به شرح زیر است:
درجه تفکیک نمونهها: ۲۰۰ نقطه بر اینچ
تعداد کل نمونهها: ۱۰۲۳۵۲ نمونه
تعداد نمونههای آموزش: ۶۰۰۰ نمونه از هر کلاس
تعداد نمونههای آزمایش: ۲۰۰۰ نمونه از هر کلاس
سایر نمونهها: ۲۲۳۵۲ نمونه
تعداد نمونه ها در هر كلاس
| رقم ٠ | رقم ١ | رقم ٢ | رقم ٣ | رقم ٤ | رقم ٥ | رقم ٦ | رقم ٧ | رقم ٨ | رقم ٩ |
| 10070 | 10330 | 9923 | 10334 | 10333 | 10110 | 10254 | 10363 | 10264 | 10371 |
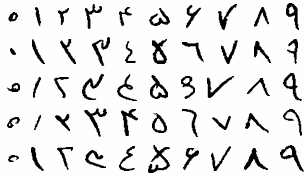 نمونه هایی از دستخط های مختلف موجود در مجموعه ارقام دستنویس
نمونه هایی از دستخط های مختلف موجود در مجموعه ارقام دستنویس
{kind=link}
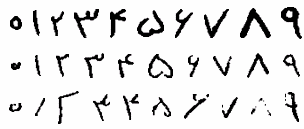 نمونه هایی از کیفیتهای مختلف موجود در مجموعه ارقام دستنویس
نمونه هایی از کیفیتهای مختلف موجود در مجموعه ارقام دستنویس
توضيحات بيشتر در مورد اين مجموعه داده را از مقالهی زير دریافت کنید.
Introducing a very large dataset of handwritten Farsi digits and a study on their varieties
اين مجموعة داده تنها برای استفادهی تحقیقاتی رايگان بوده و استفادهی تجاری از آن منوط به کسب اجازه از ماست. برای خواندن مجموعهی داده که در قالب فایلی با پسوند cdb. است کدهای C++، Matlab و یا دلفی آن را دريافت کنيد. کد پایتون هم توسط آقای امیر سانیان و نیز آقای علیرضا فرزین پور (Persian_Handwritten_Digit_Recognition) تهیه شده است.
دریافت مجموعهی دادهی هدی برای استفادهی تحقیقاتی
برخی مقالاتی که روی این مجموعه داده کار کرده اند در انتهای متن انگلیسی لیست شده اند، شما هم اگر روی این مجموعه داده کار کردهاید، لطفا ما را مطلع کنید تا مقاله شما اضافه شود.
1. “بازشناسی ارقام و حروف دستنویس در فرمهای آزمون سراسری”، پايان نامهی کارشناسی ارشد، حسین خسروی، دانشگاه تربيت مدرس ، 1384
2. فرمهای مورد پردازش در اين پروژه از طريق شرکت هوش مصنوعی هدی سيستم تهيه شده است.
——————————————————————————————————————————————
HODA Farsi Digit Dataset
HODA dataset is the first dataset of handwritten Farsi digits that has been developed during an MSc. project in Tarbiat Modarres University entitled: Recognizing Farsi Digits and Characters in SANJESH Registration Forms. This project has been carried out in cooperation with Hoda System Corporation. It was finished in summer 2005 under supervision of Prof. Ehsanollah Kabir.
Samples of the dataset are handwritten characters extracted from about 12000 registration forms of university entrance examination in Iran. The dataset specifications is as follows:
Resolution of samples: 200 dpi
Total samples: 102,352 samples
Training samples: 60,000 samples
Test samples: 20,000 samples
Remaining samples: 22,352 samples
Number of samples per each class
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10070 | 10330 | 9923 | 10334 | 10333 | 10110 | 10254 | 10363 | 10264 | 10371 |
Samples with different writing styles in the dataset
Samples with different qualities in the dataset
For more information please refer to the paper: Introducing a very large dataset of handwritten Farsi digits and a study on their varieties
This dataset is free of charge for research purposes and non commercial uses only. For commercial purposes please
This e-mail address is being protected from spambots. You need JavaScript enabled to view it
.
Download Farsi Digit Dataset for non commercial use only.
To read the dataset please download Matlab, C++ or Delphi codes.
Some articles which used this dataset for their evaluation:
1. Divide & Conquer Classification and Optimization by Genetic Algorithm
2. A New Approach to Improve the Vote-Based Classifier Selection
5. Invariance analysis of modied C2 features: case study handwritten digit recognition
6. بهبود روش استخراج ویژگی گرادیان مبتنی بر تبدیل گسسته كسینوسی جهت بازشناسی ارقام دست نوشته فارسی
آخرین دیدگاهها