
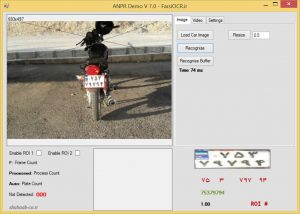
در نسخه 7.2 کتابخانه پلاک خوان ساتپا، امکان خواندن پلاک موتور و مناطق آزاد فراهم شد. برای کسب اطلاعات بیشتر و تهیه این نسخه به صفحه اختصاصی کتابخانه پلاکخوان مراجعه کنید. پلاک موتور شامل دو سطر عددی است و پلاک مناطق آزاد شامل 5رقم است که با تغییراتی در کد ++C کتابخانه، امکان شناسایی این پلاکها محقق شد....
اطلاعات بیشتر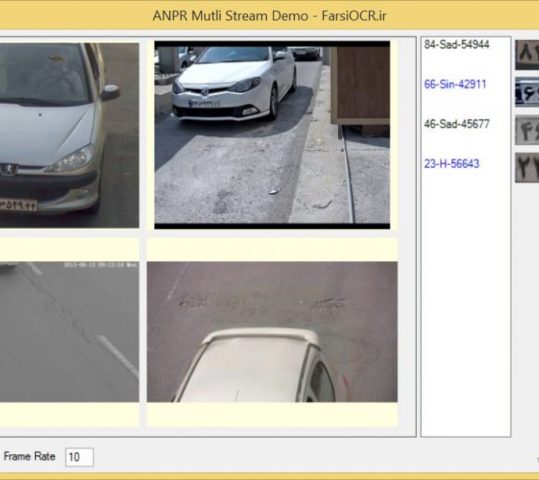
نسخه جدیدی از کتابخانه پلاکخوان ساتپا، با قابلیت اتصال همزمان به حداکثر 10 دوربین به بهره برداری رسید. این نسخه با بازبینی اساسی کدهای کتابخانه و تغییراتی در ساختار برنامه همراه بود طوری که امکان اتصال همزمان به 10 دوربین بدون ایجاد تداخل فراهم شده است. در نسخه های قبلی کتابخانه پلاکخوان در صورت اتصال به بیش از یک دوربین، به دلیل وجود منابع مشترک، گاهی اوقات برنامه هنگ می کرد که این موضوع با تغییر ساختار برنامه و حذف کامل منابع مشترک، به کلی برطرف شده است. همچنین در این نسخه، برخی باگهای گزارش شده رفع شده است. امکان خواندن پلاک موتور و پلاک مناطق آزاد مثل بندر انزلی و منطقه آزاد اروند هم تقریبا نهایی شده است که در به روز رسانیهای آتی، نهایی خواهد شد. جهت تهیه این نسخه به صفحه اختصاصی کتابخانه پلاکخوان مراجعه کرده یا با ما تماس بگیرید. توضیح برنامه دموی نسخه 7 در یوتیوب:...
اطلاعات بیشتر
پیرو تقاضای عدهی زیادی از مشتریان محترم در خصوص نسخه اندروید کتابخانه، بالاخره نسخه اندروید آماده شد. این نسخه در حال حاضر تنها با عکس کار می کند که عکس می تواند از دوربین تهیه شود یا از گالری انتخاب شود. دقت این نسخه مشابه نسخه ویندوزی است و سرعت اجرای آن بسته به نوع گوشی چیزی بین 100 میلی ثانیه تا 1 ثانیه است. باتوجه به مشکلاتی که در انتقال کدهای موجود توسط NDK وجود داشت، این کتابخانه برای اندروید کاملا بازنویسی شده است. فعلا این کتابخانه تنها به صورت سورس کد به فروش می رود و فروش فایلهای باینری منوط به یافتن راهی برای پیشگیری از هک شدن کدهای جاواست! به منظور تهیه این نسخه از کتابخانه به صفحه اختصاصی کتابخانه تشخیص پلاک مراجعه کنید....
اطلاعات بیشتر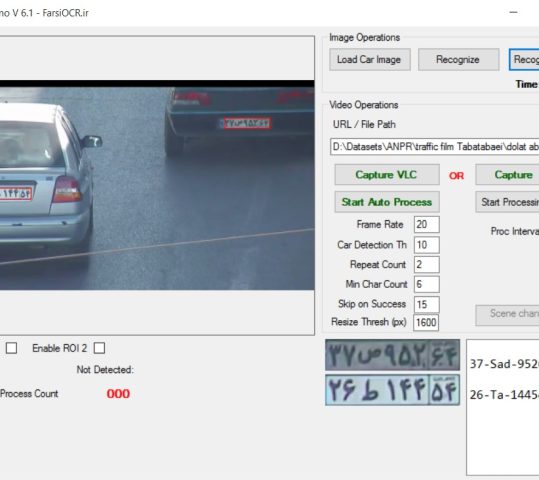
با اعمال تغییراتی در کتابخانه تشخیص پلاک ساتپا، نسخه چند پلاکه آماده شد. در این نسخه تمام پلاکهای موجود در تصویر خوانده شده و به برنامه میزبان گزارش می شود. زمان پردازش هر فریم برای رزولوشن 2 مگاپیکسل روی پردازنده Core i7 حدود 150 میلی ثانیه است. هزینه این نسخه، 25% بیش از هزینه نسخه تک پلاکه است. برای دیدن لیست قیمت نسخه تک پلاکه می توانید به صفحه اختصاصی کتابخانه پلاکخوان مراجعه...
اطلاعات بیشتر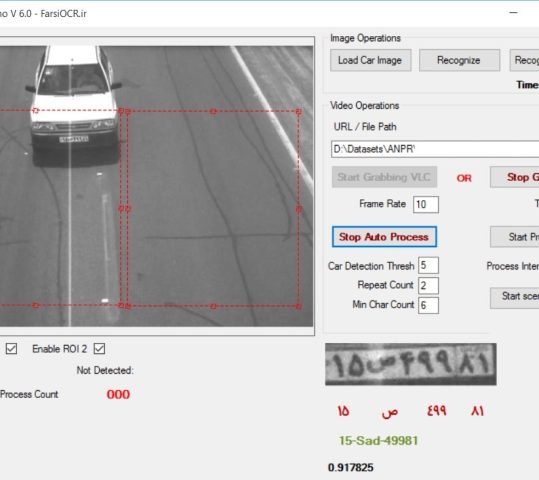
با دریافت مستمر پیشنهادات مشتریان، روز به روز کتابخانه تشخیص پلاک ستــپا غنی تر و بهتر می شود. در آخرین به روزرسانی که حاصل تلاش سه چهارماهه است، نسخه 6 کتابخانه آماده شد. عمده تغییرات این نسخه به شرح زیر است: اصلاح کد++C و رفع تمام warningهای کامپایلر رفع یک باگ مهم در بخش پردازش موازی کتابخانه که گاهی اوقات منجر به بسته شدن کتابخانه می شد امکان تعریف 4 ناحیه مورد علاقه به منظور پوشش چهار باند مختلف جاده بهبود دقت پردازش برای پلاکهای ریز و مخدوش گزارش دادن فریمهایی که حاوی خودرو هستند ولی پلاک آنها شناسایی نشده است بهینه سازی فرایند نمایش فریمها در سی شارپ ارتقاء نسخه OpenCV به 2.4.10 انشاءالله در آینده نزدیک با استفاده از قابلیتهای پردازش موازی کارت گرافیک به کمک بسترهای OpenCL و CUDA سرعت پردازش فریمها را بیش از پیش ارتقاء خواهیم...
اطلاعات بیشتر
نسخه 1.5 نویسه خوان پرشیانگار منتشر شد. مهمترین تغییر این نسخه، اضافه شدن قالب خروجی word است. به این ترتیب که در فایل خروجی شما می توانید تصاویر را هم در کنار متن داشته باشید. علاوه بر این، رابط کاربری کمی بهبود پیدا کرده است و برخی باگهای نرم افزار رفع شده است. برای کسب اطلاع از قیمت و نحوه خرید به صفحه سفارش پرشیانگار مراجعه...
اطلاعات بیشتر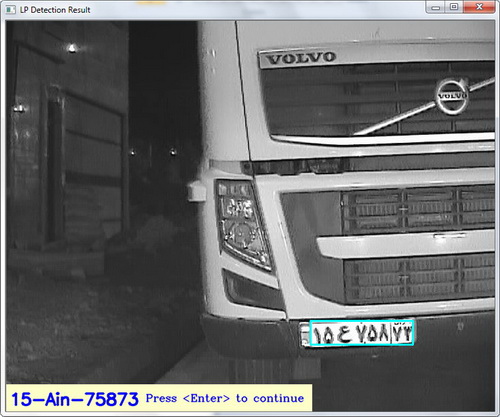
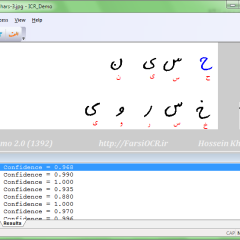
ستپا سامانه تشخیص پلاک خودروهای ایرانی است که به زبان ++C نوشته شده است. در این سامانه از تکنیکهای پردازش تصویر و شناسایی الگو کمک گرفته شده و با دقت بسیار زیاد، موقعیت پلاک و حروف پلاک شناسایی میشود. این سامانه در قالب یک کتابخانه قابل استفاده در زبانهای C++ ، C، دلفی و #C است. برای برخی پردازشهای مقدماتی از قابلیتهای ساده OpenCV هم کمک گرفته شده است لیکن بخش عمده برنامه مستقل از OpenCV است. برای کسب اطلاعات بیشتر، و دانلود برنامه نمونه، لینک زیر را باز کنید. کتابخانه تشخیص پلاک خودرو به زبان C++ به همراه سورس...
اطلاعات بیشتر



